说实话,写这篇文章的时候,我还是很激动的
因为这是我第一次爬虫实战
好的,废话不多说,我们进入正题
今天我们要爬取酷图吧下的全部图片
首先,打开酷图吧,然后用筛选选项,找出自己想要爬取的一系列图片
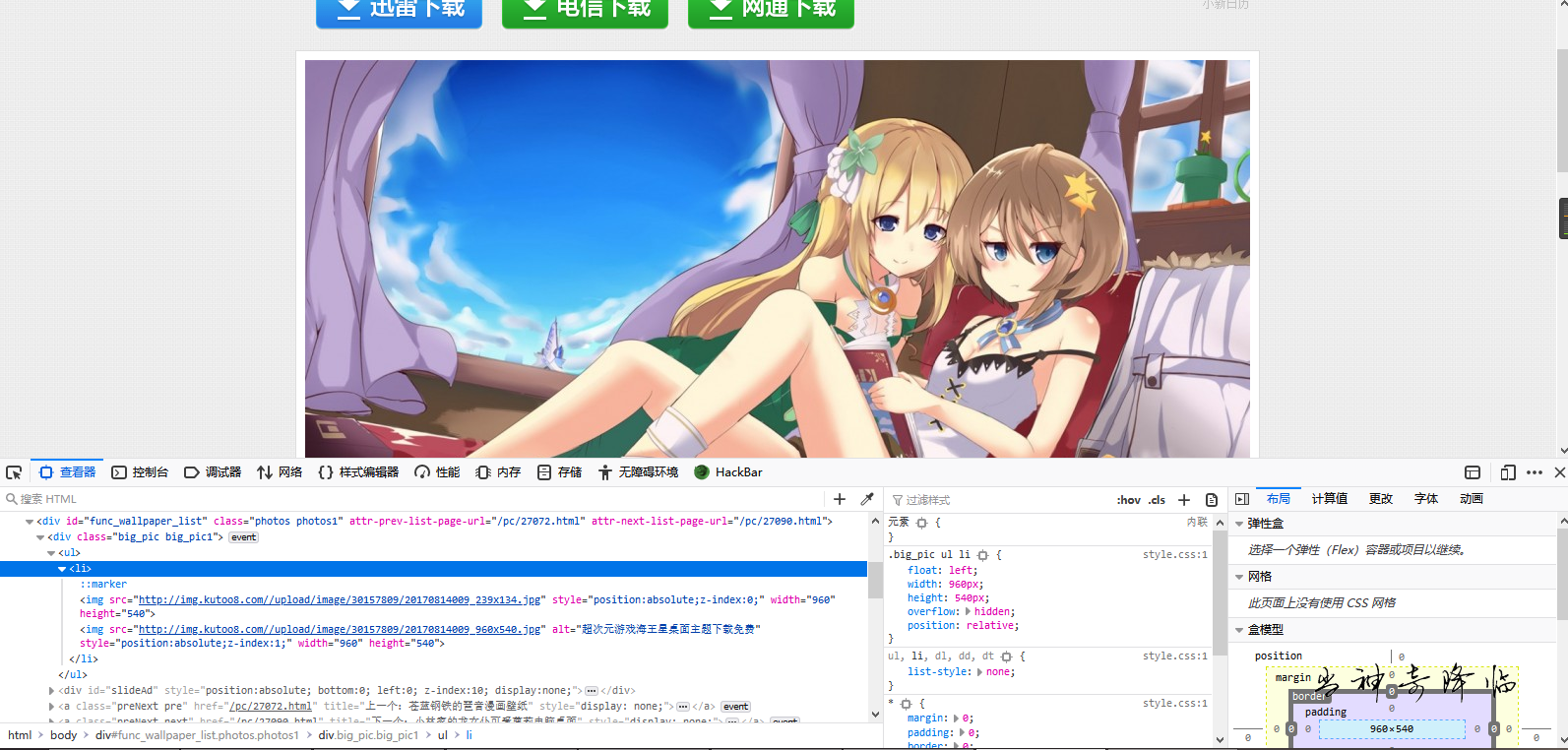
然后用审查元素,找到任意图片的位置

我们可以看到,这个缩略图的url是:
http://img.kutoo8.com//upload/image/30157809/20170814009_228x128.jpg
然后点入文章页,我们继续找更高清晰度的图片url
使用审查元素,我们发现如下两个链接
http://img.kutoo8.com//upload/image/30157809/20170814009_239x134.jpg
http://img.kutoo8.com//upload/image/30157809/20170814009_960x540.jpg
将前面找到的缩略图url放在一起,然后再找几组图片的链接,我们找一下规律
http://img.kutoo8.com//upload/image/30157809/20170814009_228x128.jpg
http://img.kutoo8.com//upload/image/30157809/20170814009_239x134.jpg
http://img.kutoo8.com//upload/image/30157809/20170814009_960x540.jpg
http://img.kutoo8.com//upload/image/33745267/20170814008_228x128.jpg
http://img.kutoo8.com//upload/image/33745267/20170814008_239x134.jpg
http://img.kutoo8.com//upload/image/33745267/20170814008_960x540.jpg
对比两组图片,有什么发现呢?
我们发现,图片url由三个部分组成
1.代表图片序号的前半部分,如:http://img.kutoo8.com//upload/image/33745267/20170814008_
2.代表图片大小的第二部分,如:960x540
以及最后图片的后缀.jpg
换一种思维,也就是我们可以直接从图片列表里,获取像素较小的图片缩略图的url,然后通过修改图片的url,找到需要的图片大小,再进行下载
整理思路,我们获得如下列表
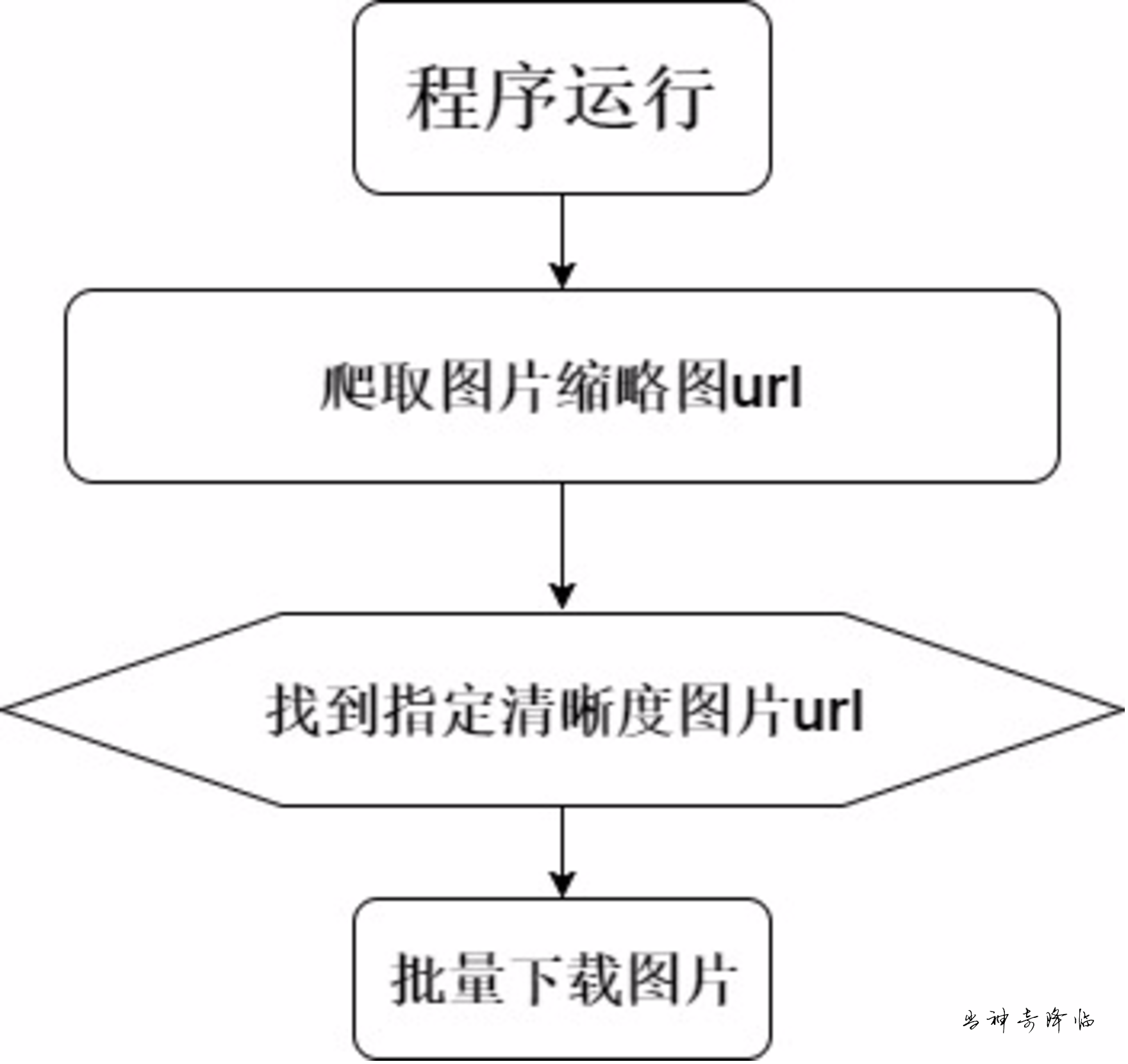
从整理的框架上来看,制作这个工具需要用到一下几个模块
- requests 连接网站,发送请求
- xpath 从网站中提取图片url
- time模块 防止爬虫访问过快,导致网站崩溃(这个网站似乎性能不咋地)
既然思路已经整理好了,,,那么。。。
码字开始!
1.导入模块
首先,我把导入必要模块
import requests
from lxml import etree
import time
2.发送请求
导入模块后,我们需要给酷图吧发送一个请求,获取网站的代码
response = requests.get(url)
html = response.text
html = etree.HTML(html)
3.提取图片url
然后,在从网站上获取的代码中,找到图片的url
这是我们就可以用到xpath了
先用审查元素,找到图片的位置


对比两个图片的url在代码中的位置
我们可以找到索引中,图片位置的共同点
然后利用xpath将图片url提取
photo_src = html.xpath('//div[@class="pic"]/a/img/@data-original')
4.导出图片url
获取图片url后,我们需要将图片的url提取,然后再进行下载
创建一个保存url用的空白文件,然后将url逐个导入
代码如下
response = requests.get(url)
html = response.text
html = etree.HTML(html)`
5.设置批量
上面的这些代码写了后,还有个问题
我们需要的是爬取整个网站内需要的图片,而不是一页
也就是说,我们需要知道,搜索中每一页的url
从第一页开始,一页一页的找网站的url,进行比较,然后寻找规律
http://www.kutoo8.com/pc/dongman/1920x1080/zuixin/
http://www.kutoo8.com/pc/dongman/1920x1080/zuixin/2.html
http://www.kutoo8.com/pc/dongman/1920x1080/zuixin/3.html
http://www.kutoo8.com/pc/dongman/1920x1080/zuixin/4.html
http://www.kutoo8.com/pc/dongman/1920x1080/zuixin/5.html
http://www.kutoo8.com/pc/dongman/1920x1080/zuixin/6.html
http://www.kutoo8.com/pc/dongman/1920x1080/zuixin/7.html
对比其他搜索的页面,我们可以很容易的发现,页面的组成结构
http://www.kutoo8.com/ + 用户端(手机或电脑)/ + 搜索内容 / + 图片大小/zuixin/ + 页数 + .html
既然知道了页面的结构
发现了这个规律,那我们很容易就可以找到解决的方法 --写一个循环语句,拼出所有要爬取页面的url
这里我就用动漫的为例子
`none = 1
while True:
none += 1
if none = 59: #因为一共就58页
break
else:
pass`
6.程序完成,开始爬取url
写到这里,程序已经大体讲清楚了
然后我们把上面讲的内容,按照逻辑顺序凭借,程序就可以运行了
运行程序,提取url

7.下载图片
url提取好了,当然是要下载了
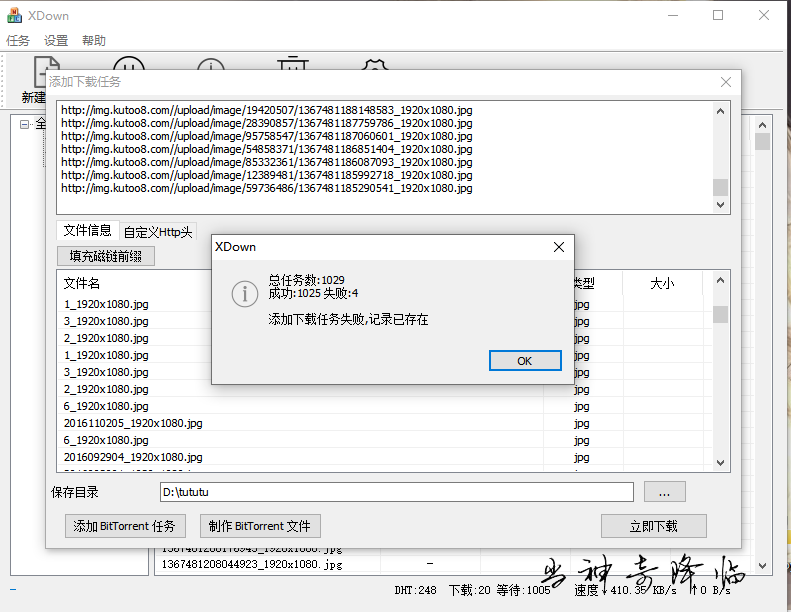
这里我给你们推荐一个下载器
将要下载的图片url放入xdown,然后设置下载的路径,就可以愉快的下载图片了呦!

最后,附上源码(写的有点乱,表介意)点我下载
原创不宜,可以的话,给个评论再走呗
以及。。转载别忘了写转载申明哦!
版权属于:神奇
本文链接:http://magic921.com/329.html
转载时须注明出处及本声明